
Response AI step
We encourage all our users to use the Prompt step moving forward for all their AI responses.
The Response AI step let you leverage the power of LLMs like GPT 4 to respond through text in your Voiceflow agents.
Response or Set AI?
- Response AI: This displays the AI response directly to the customer. You can select the Knowledge base or the AI model directly as the data source. This supports Markdown formatting.
- Set AI: This saved the AI response to a variable. So the user never sees it. Mastering the Set AI step is key to developing an advanced agent, as it allows you to do prompt chaining. You can learn more about it here.
Both steps can either directly use models, or also respond using your Knowledge Base.
Adding an AI Step to your Assistant
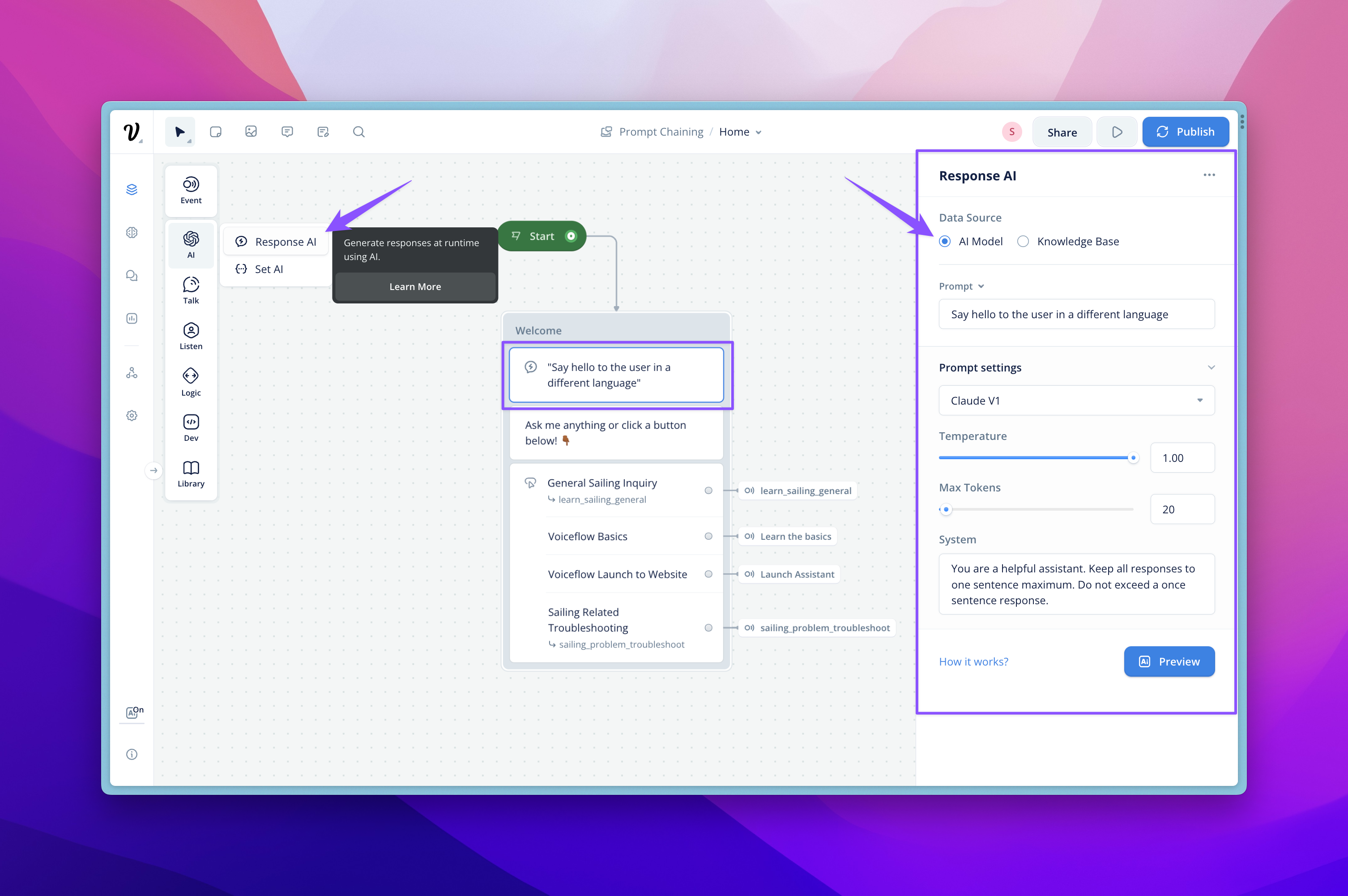
Once enabled, you can find the Response AI Step in your Assistant's Steps Menu, under the AI section. The step can be added into your Assistant anywhere that you might add a Text or Speak Step. Once you have placed your step, you can configure it in the Editor.
To configure your generative response, in the Prompt field, provide a description of the type of response you'd like the AI to generate. You can leverage variables from your project within this prompt, to make it dynamic. You have two options for the Data Source your LLM will leverage: AI Model or Knowledge Base. Default setting is AI Model.
Configuring your Prompt
There are currently 4 ways to configure the prompt you've provided to modify the potential output:
- Model — This is the model that will be used to created your prompt completion. Each model has its own strengths, weaknesses, and token multiplier, so select the one that is best for your task.
- Temperature — This will allow you to influence how much variation your responses will have from the prompt. Higher temperature will result in more variability in your responses. Lower temperature will result in responses that directly address the prompt, providing more exact answers. If you want 'more' exact responses, turn down your temperature.
- Max Tokens — This sets the total number of tokens you want to use when completing your prompt. Greater max tokens means more risk of longer response latency.
- System — This is the instruction you can give to the LLM model to frame how it should behave. Giving the model a 'job' will help it provide a more contextual answer. Here you can also define response length, structure, personality, tone, and/or response language. System instructions get combined with the question/prompt, so be sure they don't contradict.
Testing your Generated Responses
You can test your prompt using the Preview button, which will ask you to provide an example variable value if you have included one.
When you run your Assistant in the Test Tool or in Sharable Prototypes, any Generate Steps you have configured will be active, generating their response content dynamically.
Updated 6 months ago